
検索エンジンは、インターネット上の膨大な情報を収集、整理し、ユーザーの検索クエリ(検索意図)に対して最適な回答を順位付けして提供します。この一連のプロセスは、SEO(検索エンジン最適化)を遂行する上で、正確に理解すべき基礎知識です。
本記事では、検索エンジンの仕組みの基盤となっている「クローリング」「インデックス」「ランキング」という3つの主要なプロセスについて、その技術的な側面とSEO施策との関連性に焦点を当てて解説します。
まず、最初に以下にて「クローリング」「インデキシング」「ランキング」のプロセスを図解したイメージ図をお見せします。
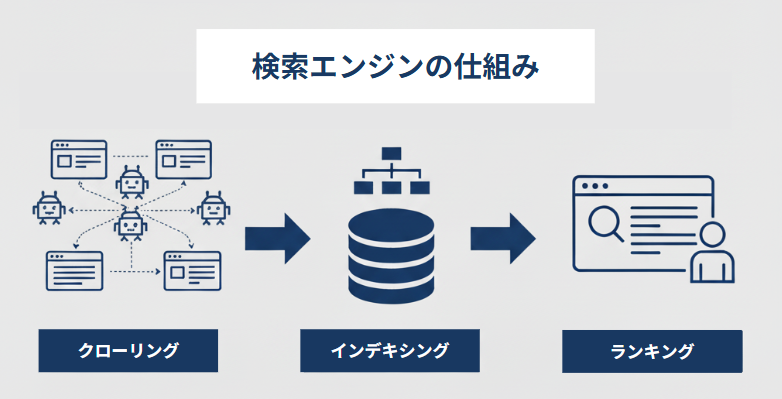
検索エンジンは、上図のように検索ボットがインターネット空間のWebサイト(Webページ)を回遊し、データベースサーバーへ格納(インデックス化)し、ランキング生成するという一連のプロセスを踏みます。
それでは早速、この3つのプロセスについて、それぞれ具体的かつ詳細に説明していきます。
目次
クローリング (Crawling) :Webページの発見と巡回
クローリングは、検索エンジンがインターネット上に存在するWebページを発見し、その情報を収集する最初のプロセスです。
クローリングのプロセス
このプロセスは、「クローラー」(または「ボット」)と呼ばれる検索エンジンの自動化プログラムによって実行されます。クローラーは、既知のURLリスト(過去のクロール結果やサイト運営者から提供されたXMLサイトマップ)を起点に、HTML上のハイパーリンク(<a>タグ)をたどり、新しいページや更新されたページを継続的に発見・巡回します。
収集されたページデータ(HTML、CSS、JavaScript、画像、PDFなど)は、次のインデックスプロセスのために検索エンジンのサーバーに送信されます。
クローラビリティ(Crawlability)の最適化
クローラーによる効率的な巡回(クローラビリティ)は、SEOの土台となります。担当者は以下の点に注意する必要があります。
- XMLサイトマップ (sitemap.xml) の送信:
クローラーに対してサイトのURL構造を明示的に通知し、重要なページの発見を促します。Google Search Console経由でのサイトマップ送信は必須の施策です。 - 内部リンク構造の最適化:
論理的で階層化された内部リンク構造は、クローラーがサイトの深層にあるページにも到達するのを助けます。関連性の高いコンテンツ同士を適切にリンクさせることが重要です。 - robots.txt の精査:
クローラーのアクセスを制御するファイルです。Disallow ディレクティブによって重要なページやリソース(CSS/JSファイル)が誤ってブロックされていないか、定期的な確認が必要です。 - クロールバジェット(Crawl Budget)の意識:
(主に大規模サイトにおいて)クローラーが1つのサイトに割り当てるリソース(時間やリクエスト数)は有限です。低品質なページや重複コンテンツを放置すると、重要なページのクロール頻度が低下する可能性があります。
インデックス (Indexing) :データベース登録
クローリングによって収集されたデータは、次に「インデックス」プロセスに移行します。
インデックスのプロセス
インデックスとは、収集されたページ情報を検索エンジンが解析・理解し、「インデックス」と呼ばれる巨大な分散データベースに登録・整理するプロセスです。
この段階で、検索エンジンは以下の処理を行います。
- レンダリング:
HTML、CSS、およびJavaScript(クライアントサイドレンダリング含む)を実行し、ユーザーがブラウザで見る状態と同様にページを構築(レンダリング)します。 - コンテンツ解析:
テキストコンテンツの抽出、<title>タグや<h1>などの見出しタグの識別、画像(alt属性含む)や動画の認識、構造化データ(Schema.org)の解釈を行います。 - 正規化:
URLの正規化(wwwの有無、index.htmlなど)や、重複コンテンツの判定(canonicalタグの参照)を行い、どのURLをインデックスの「代表」とするかを決定します。
インデックスに登録されて初めて、そのページは検索結果の候補となります。
インデクサビリティ(Indexability)の最適化
ページが正しくインデックスされるよう、以下の制御が不可欠です。
- noindex タグの確認:
<meta name=”robots” content=”noindex”> タグは、ページをインデックスから除外する強力な指示です。テスト環境での設定が本番環境に残存していないか、意図せず重要なページに使用されていないかを確認します。 - canonical タグの適切な使用:
パラメータが付与されたURLや重複コンテンツが存在する場合、rel=”canonical” を使用して正規URLを明示し、評価の分散を防ぎます。 - コンテンツ品質の担保:
極端に情報量が少ない、または他サイトからのコピーで構成されるページは、インデックスされない(または削除される)可能性があります。
ランキング (Ranking) :検索クエリに対する順位付け
インデックスされたページ群は、ユーザーの検索クエリが発生した瞬間に「ランキング」プロセスの対象となります。
ランキングのプロセス
ランキングとは、特定の検索クエリに対して、インデックスデータベース内から関連性の高いページを抽出し、それらを検索エンジンの複雑なアルゴリズムに基づいて順位付けするプロセスです。
このアルゴリズムは数百の「シグナル(評価要素)」から構成されており、ユーザーに最も有益で信頼できる回答を提供することを目的に設計されています。
主要なランキングシグナル
アルゴリズムの全容は非公開ですが、Googleが重要視しているシグナルは公表されています。SEO担当者はこれらの要素を継続的に改善する必要があります。
検索クエリとの関連性
クエリの意図と、ページコンテンツ(タイトル、見出し、本文)の一致度。単なるキーワードの含有率ではなく、トピックの網羅性や文脈的な一致が評価されます。
コンテンツの品質と E-E-A-T:
- Experience (経験): コンテンツ作成者がそのトピックを直接経験しているか。
- Expertise (専門性): 作成者がその分野の専門家であるか。
- Authoritativeness (権威性): サイトや作成者がその分野で権威ある存在として認識されているか(被リンクや言及など)。
- Trust (信頼): サイトの透明性、情報の正確性、運営者情報の明示。
ユーザビリティ(UXシグナル)
Core Web Vitals (LCP, FID/INP, CLS): ページの読み込み速度、インタラクティブ性、視覚的安定性。
モバイルフレンドリー: モバイルデバイスでの閲覧・操作性。
HTTPS: セキュアな接続が提供されているか。
ユーザーの文脈
検索が行われた地理的位置、過去の検索履歴、使用デバイス(PC/モバイル)など、ユーザーの状況に応じて最適な結果を提供するよう調整されます。
まとめ
SEO担当者は、「クローリング」「インデックス」「ランキング」が独立したプロセスではなく、連続したフローであることを強く認識する必要があります。
- クローリングされないページは、インデックスされない。
- インデックスされないページは、ランキングの対象にならない。
- ランキングは、インデックスされたページ群の中で行われる相対的な評価である。
SEO施策とは、これら3つのプロセスすべてにおいて、技術的および内容的な最適化を継続的に行う活動に他なりません。
自サイトのコンテンツが検索エンジンによって正しく発見(クロール)される。そして、正確にインデックスされ、ユーザーにとって最も有益であると高く評価(ランキング)されるように日夜改善を続けることが重要なのです。